30.07.2009
(c) 2006, 2007, 2008, Heartsome
Europe GmbH
142




Heartsome Europe GmbH
www.heartsome.de
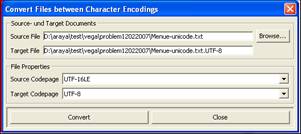
Converting
Files between different Character
Encodings
This function supports converting files between
different character sets. Depending on the target character up to two files are written. If the target
file is a UTF-8, 16, 32 or UCS file, two files are written. The second file with the extension „.nobom“ is a copy of the first target file, the only difference is that the BOM
(Byte Order Marks) are
removed from this file. This file should be used for importing, esp. when an import of
an UTF-8 file
is done in Araya, as the Java reading functions for UTF-8 does not over read
the BOM characters. This could lead to problems when reading normal
strings from those file as the BOMs are read as normal characters resulting in invalid
entries.
(This is a known bug in Java UTF-8 file
reading, but will not be corrected by SUN!).
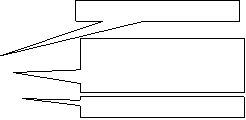
Source file name
Target file; will be created based on source file name and as extension the target encoding character set
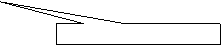
Source encoding character set
Target encoding character set